|
Title: Increasing the equitability of data citation in paleontology: capacity building for the big data future Authors: J.A. Smith, N.B. Raja, T. Clements, D. Dimitrijević, E. M. Dowding, E.M. Dunne, B.M. Gee, P.L. Godoy, E.M. Lombardi, L.P.A. Mulvey, P.S. Nätscher, C.J. Reddin, B. Shirley, R.C.M. Warnock, Á.T. Kocsis Journal: Paleobiology DOI: 10.1017/pab.2023.33 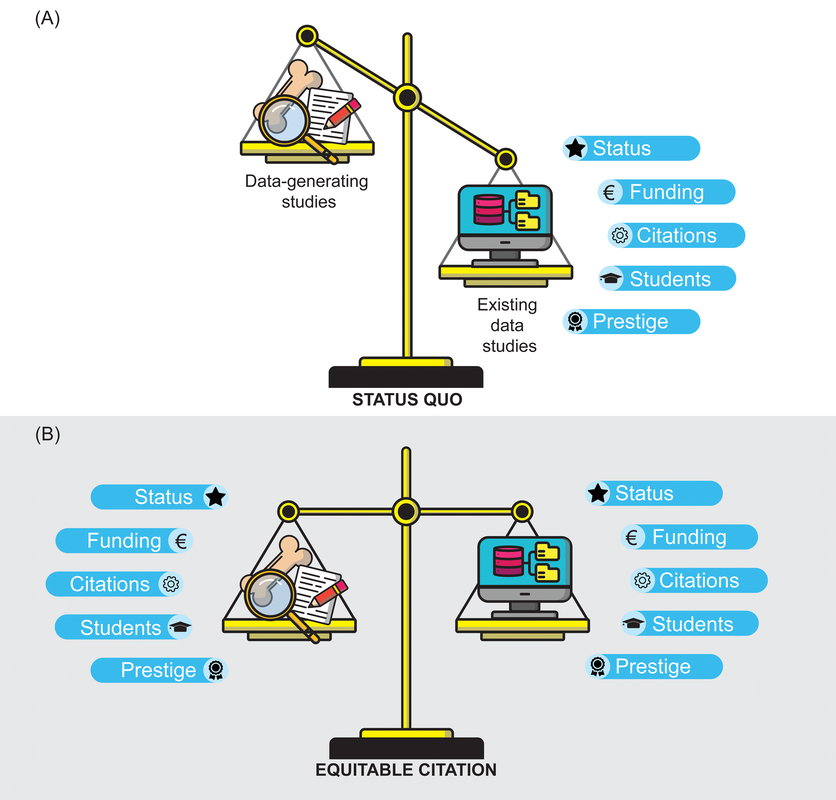 Figure 1 from the paper: "The current balance of credit distribution in paleontology (A) and a reimagined dynamic in which data-provisioning publications are equitably cited (B)." General summary (pulled direct from the non-technical summary available with the paper): Researchers often use large databases to conduct their studies; however, they do not always provide credit, through citations, to the people who produced the data in the databases. In the field of paleontology, researchers use a large database called the Paleobiology Database (PBDB) to study global patterns and processes over millions of years. These studies use data from the PBDB and typically receive a greater number of citations than the original data-producing papers. This creates a situation where the hard work of collecting the data is not credited and rewarded in a fair way, even though this work is equally important to the field of paleontology. By fixing this issue and giving proper credit to data-producing papers, paleontology itself can be strengthened by increasing the incentives for producing data and at the same time creating more high-quality data for everyone to use. Remember your roots Paleontology has historically been a descriptive discipline, focused on describing new fossils, which in turn may represent new species and/or new occurrences (in space and/or time). This is hardly exclusive to paleontology – all natural history disciplines (e.g., geology, other life science sub-disciplines like herpetology or ichthyology) are rooted in simply describing observations. Even today, scientists are constantly reporting new modern occurrences, from new living species (e.g., the Lady Elliott Shrimp Goby) to finding new occurrences, like the deepest known occurrence of a fish below 8,000 m. In paleontology, descriptions of new species and new occurrences are particularly common, even today, because of the incompleteness of the fossil record and the continued erosion and exposure of new fossil-bearing rocks. Such descriptive work is a great example of primary data, which are defined as being unique and novel, or data-generating in the parlance that is used in the above figure (data-provisioning for most of the rest of the paper). This is contrasted with secondary data, which are existing data that are being reused in some form, such as by downloading data from a database that has aggregated primary data from many different sources; a good summary of the distinction can be found here. Because primary data collection involves novel data generation, it is typically (though hardly always) more time-intensive and costly (this should not be misconstrued to mean that secondary data analyses are not or cannot be time-intensive or costly). In paleontology, the official publication of a novel occurrence involves a lot more than just the examination of the fossil and writing it up; it requires someone to have found the fossil to begin with, which is often a resource-intensive process that involves identifying potential fossil-bearing areas, surveying said areas, actually finding a fossil, collecting it, and preparing it. As a result, many data-generating paleontological studies are at a very specific scale (e.g., a single fossil or a set of fossils from one site). Some examples of my primary-data-generating studies from 2023:
The next frontier The vast majority of paleontological work has historically centered on generating primary data because that was the only thing that was really feasible until computers and other technological advancements permitted more comprehensive, and often intensive, analyses that are based on aggregating data together from many sources. Today, such studies are far more tractable and thus far more common, not just for paleontology but across all disciplines (AI being the most prominent recent development that may further expand the research horizons). We also have a variety of openly available databases that aggregate hundreds of thousands of published records, such as the Paleobiology Database (PBDB). A secondary data source could thus be generated in a matter of mere minutes but end up comprising thousands of unique records, each requiring hundreds of hours to have produced. These secondary data studies can take on a variety of forms, such as meta-analyses, bibliometric analyses, or the umbrella term of 'big data' studies; all share a commonality of collating data from many sources in order to create a larger sample size that can be used to tackle questions at larger scales. Some examples from Emma Dunne, one of the other authors on this paper:
A numbers game Academics, like many people, prefer hard numbers (quantitative) to relative assessments (qualitative). Therefore, we often rely on various imperfect numerical metrics and proxies to attempt to assess research (and researcher) quality. Two examples are impact factor (IF) and citation count. Impact factor is a journal-specific metric and is calculated as follows:
Journals with a higher IF are viewed as being more prestigious (selective about what they publish), and even though there are many reasons why a journal's IF does not have much of any bearing on the direct quality of a single article or the researchers who published it, remains a popular metric. For example, Nature and Science, two journals considered among the most prestigious journals across many disciplines, have two-year IFs of 64.8 and 56.9. By comparison, journals like the Journal of Paleontology and the Journal of Vertebrate Paleontology have two-year IFs below 3.0 and are thus considered much less prestigious. Because secondary data studies aggregate data, they can tackle questions that are "bigger picture" and are thus more appealing to selective journals that aren't interested in publishing a description of a new fossil (unless it's a dinosaur or something very cool). As a result, data-generating studies are often published in society journals (e.g., Journal of Paleontology, Acta Palaeontologica Polonica, Journal of Vertebrate Paleontology) that are not considered prestigious. IF is based on citation count, but citation counts can also be used on their own (e.g., a researcher can list the citation counts for all of their articles on their CV) – this can also be used as a semi-quantitative assessment of the quality of research (on the premise that high-quality work is cited more often), but there are also many flaws with correlating citation counts with research(er) quality. The problem
Most researchers are predominantly either data generators or data reusers; this does not mean that one cannot be both, but it is rare for people to be frequently engaged in both forms of analysis such that they are more or less a 50-50 split. Because of the aforementioned reliance on numerical metrics like journal IF and citation counts, researchers with a publishing portfolio that is skewed towards secondary data analysis are more likely to have publications in journals with higher IFs (read as more prestigious) and thus be more competitive / attractive in everything from hiring decisions to grant awards because of a perception that their work is more important, rigorous, "big picture," or applicable when compared to researchers who are primarily data generators publishing in lower-IF journals. However, if primary data generators become increasingly less likely to be funded, the generation of primary data grinds to a halt, and this has downstream effects on what analyses can be done using secondary data when people get stuck with the same old data. Many papers, for example, have demonstrated the growing crisis associated with a lack of funding for taxonomy (e.g., Agnarsson & Kuntner, 2007; Drew, 2011; Löbl et al., 2023). There are a multiplicity of reasons why data generating studies and researchers tend to be undervalued in contemporary academia, but one of them are practices around properly citing sources. As with the citation of previous articles' findings or conclusions, secondary data studies should also be citing the data-generating studies that they rely on for the analysis, yet many fail to properly do so, leading to these gaps in quantitative metrics that lead to the devaluation of data generating research(ers). The data What this study did is put numbers on the qualitative observation that data-generating papers tend to be undercited (undercredited). In paleontology, many of the secondary data analyses rely on aggregating data from the Paleobiology Database, but many of them do not cite the data-generating studies in a way that can be tracked and thus properly credited (I think that some of my own publications have been used in PBDB studies but frankly have no clue which ones). Studies that use the PBDB (secondary data studies) are supposed to "register" in order to receive a PBDB publication number, so these can be easily identified and have their total and per year citation counts obtained/calculated via Google Scholar (orange bar below). From those studies, the data-generating studies that were used by the PBDB studies could be identified (nearly 50,000 unique studies from just 151 PBDB studies for which data could be recovered). The total and per year citation counts for those data-generating studies could then be obtained/calculated via Google Scholar (blue bar below). However, we know that Google Scholar (and every other scholarly aggregator) isn't checking things like Supplemental Information for citaitons, if they exist in the SI to begin with. The number of missed citations (i.e. not tracked by Google Scholar) of data-generating papers could subsequently be calculated from the datasets of those 151 studies (e.g., Smith et al., 2000, was used by 5 PBDB studies) and added to the total citation count (the blue-green bar below). Because not all of the PBDB studies in the focal interval (2001-2021; n=396) had their data recovered, the hidden usage/citation rate of data-generating papers could be extrapolated from the 151 PBDB studies that did have their data recovered, assuming similar usage rates over all 396 studies (the extra blue-green bar below). These extrapolated numbers result in a mean citation rate that is nearly the same as that of PBDB studies, rather than the presently recorded rate that is only about one-third of the rate. 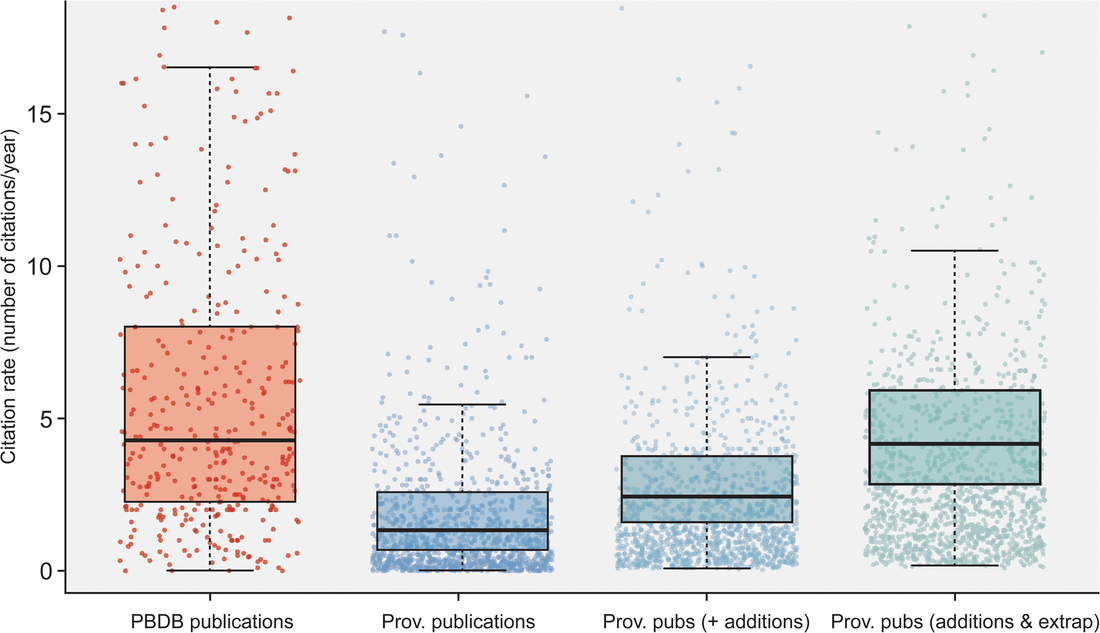 Figure 2 from the paper: "Citation rates for official Paleobiology Database (PBDB) publications and the data-provisioning publications used in those PBDB publications. Only data-provisioning publications from the same time frame (since 2001) as PBDB publications are included to standardize for temporal effects. Citations to data-provisioning publications (i.e., primary literature) are presented as the current rate (i.e., no additions for neglected citations), the projected rate when including citations from PBDB publications where data were available (k = 112; i.e., additions), and the projected rate when making those additions and extrapolating to the entire set of PBDB publications (k = 396; i.e., additions and extrapolated)." Predictably, if the true citation count of data-generating papers can be demonstrated to be higher than what is presently tracked across scholarly aggregators like Google Scholar, the journals in which these papers are typically published should also have higher impact factors than what is presently reported, and this is shown below (see the discussion in the paper for more context about different year-intervals in impact factor calculations and other historical conditions for publishing). Collectively, these analyses provide clear evidence that data-generating studies are systemically undercited, which can produce misleading perceptions of interest in and quality of these studies and the journals they are published in (even if that is in large part because we rely too much on flawed metrics to assess these). 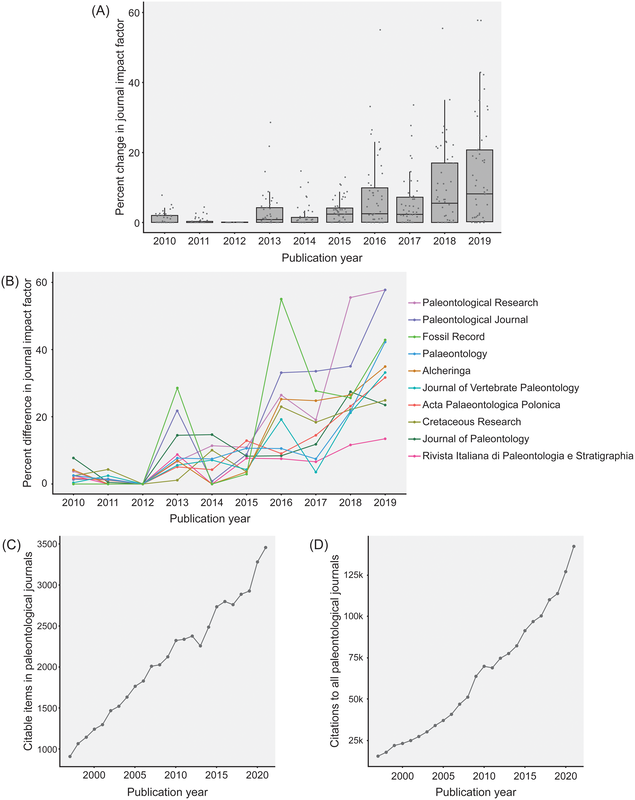 Figure 3 from the paper: "The effects of adding neglected citations from data reuse on journal impact factor (JIF; A, B) and general patterns in publishing trends in paleontology (C, D). A, The increase in JIF for the 55 journals categorized to paleontology by Clarivate, for the period of 2010 to 2019. Note, an outlier value of 172% in 2018 for PalZ was not plotted. B, Increases in JIF for the 10 paleontological journals most affected by neglected citations, only including those with complete data for the duration of 2010 to 2019. For raw data for all 55 paleontological journals from 1997 to 2021, see “7_paleo_journal_JIFcalculation.csv” in Smith et al. (2023a). C, The number of citable items published in paleontological journals each year. D, The number of citations to items published in paleontological journals each year." Don't hate the player, hate the game A lack of proper citation of data-generating studies by data-reusing studies can and certainly does result from poor research practices around citation (I often see people remove license/copyright and citation information from database downloads in my day job), but even well-intentioned researchers can frequently have their hands tied by various other factors, mainly on the end of the journals that we publish in. For example, these are some policies found across various journals that can lead to a lack of citations of primary data:
A way forward Many of these hindrances are structural at the level of a journal or publisher, so it may seem that there is little to be done to more accurately and equitably track data reuse. However, there are a variety of actions that authors can take now to try and work around these existing limitations. One example:
Finally, the biggest challenges lie in advocating for structural changes. For example, as research output rises, the incentives to perform peer review, which is practically never compensated or rewarded in any form, decline. Peer review is the primary mechanism that should be responsible for ensuring rigor of a study, which includes proper data sharing and data citation, but there is not much incentive for reviewers to even check supplemental information files if doing so would require substantial time investment. Other target areas include advocating for changes in journal policies in how citations can be provided in a format that is discoverable and indexed by the aggregators that we all rely on to track citations is the most crucial and alternative means of evaluating research quality and performance. A few journals (e.g., Global Ecology & Biogeography) do allow for references cited only in Supplemental Information to be listed in the main-text References so that they are picked up by indexers. As journal editorial boards are made up of normal (well, somewhat normal) researchers, they also have some ability to direct journal policies in a variety of ways, from formatting prescriptions to journal scope. Development and adoption of other metrics of tracking and recognizing scholarly contributions in merit-based processes, in which "normal" researchers are also directly involved, will also be critical.
0 Comments
|
About the blogA blog on all things temnospondyl written by someone who spends too much time thinking about them. Covers all aspects of temnospondyl paleobiology and ongoing research (not just mine). Categories
All
Archives
January 2024
|
 RSS Feed
RSS Feed
